





Building a Scalable and Serverless Data Pipeline on AWS Cloud
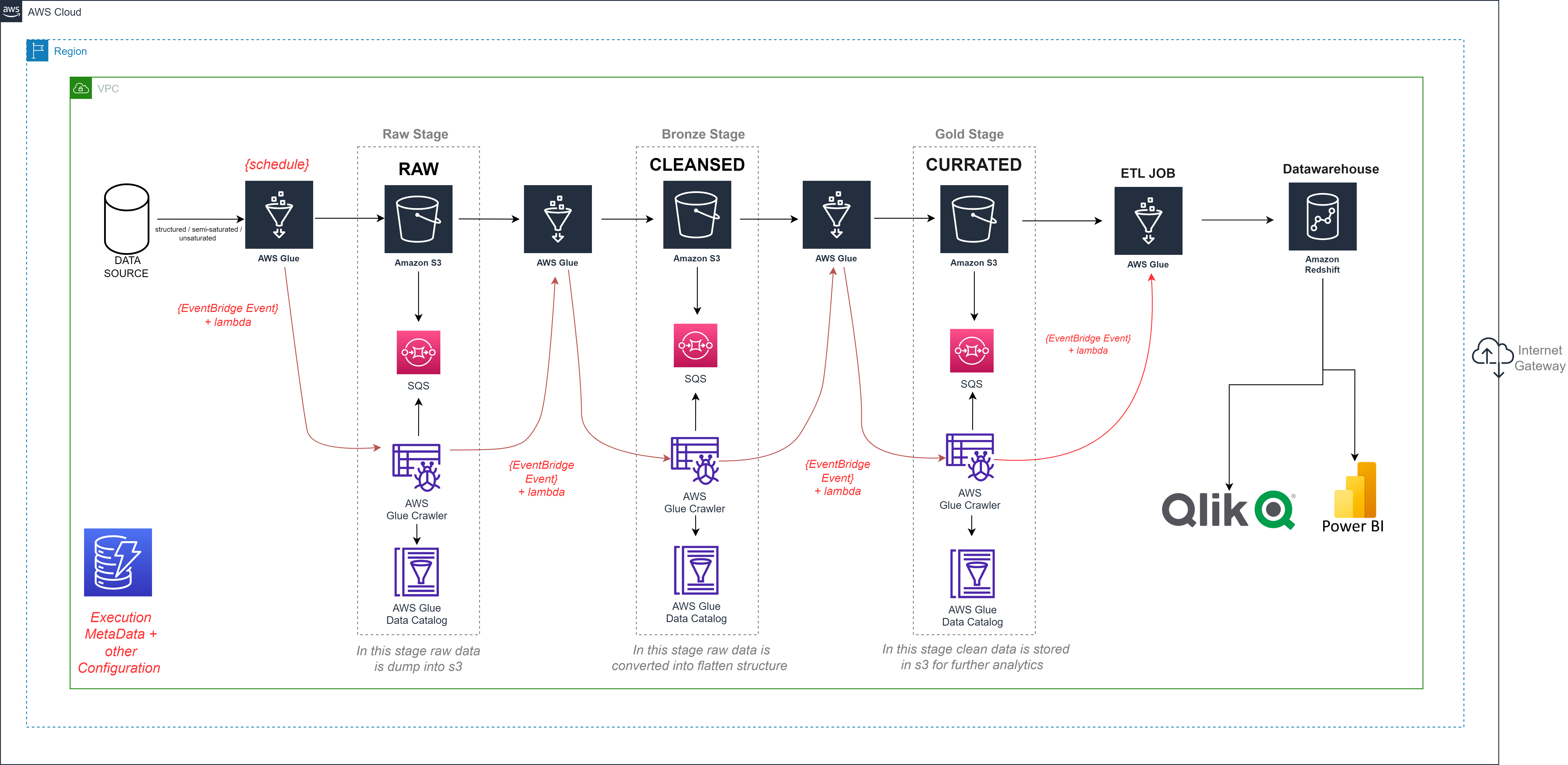
Building a production-ready data pipeline on the AWS cloud can be a complex process, but it is essential for managing and processing large volumes of data efficiently. AWS provides a suite of cloud services that can be used to build a robust and scalable data pipeline, including Amazon S3, Redshift, Glue, EventBridge, CloudWatch, Lambda, SNS Notification, and Simple Queue Service.
In stage one of the pipeline, we use AWS Glue to transform the raw data into a simple, flattened structure that can be stored in S3. This is done in three stages – the raw stage, the bronze stage, and the gold stage. In the raw stage, the data is dumped into S3 from the data source using an AWS Glue job. In the bronze stage, the data is transformed from a complex structure (e.g., nested JSON) to simple objects that can be easily processed. Finally, in the gold stage, normalized tables are created in Parquet format by another Glue job, which takes the flattened objects from the bronze stage and stores them in S3.
In stage two of the pipeline, we load the normalized data from S3 (Gold stage) into Redshift, our data warehouse, using AWS Glue. This process is efficient, reliable, and scalable, ensuring that our data is stored securely and can be accessed quickly and easily.
To automate the data pipeline, we can use DynamoDB to store the execution metadata and other configuration information. This helps to track the progress of the data pipeline and manage the configuration parameters efficiently. Additionally, we can use Simple Queue Service (SQS) to load incremental data changes from S3 into Redshift. This enables us to process only the changes in the data rather than the entire dataset, which reduces processing time and improves performance.
One of the advantages of using AWS cloud services for our data pipeline is that the entire architecture is serverless. This means that we don’t need to worry about managing servers or infrastructure, which saves time and reduces costs. Additionally, the use of EventBridge, CloudWatch, Lambda, SNS Notification, and Simple Queue Service ensures that our data pipeline is highly available, fault-tolerant, and can be easily monitored and managed.
Conclusion
Building a production-ready data pipeline on the AWS cloud offers a scalable and reliable solution for efficiently managing and processing large volumes of data. By leveraging AWS services such as Glue, S3, Redshift, DynamoDB, SQS, and others, it is possible to create a fully automated, fault-tolerant, and cost-effective data pipeline. The serverless architecture eliminates the burden of infrastructure management, allowing organizations to focus on deriving valuable insights from their data.