





Components of Data Lakehouse
In the era of big data, organizations are constantly seeking innovative solutions to store, manage, and analyze vast amounts of data. The emergence of data lakehouses has revolutionized data architecture by combining the strengths of data lakes and data warehouses into a unified and scalable platform. A data lakehouse provides the flexibility of a data lake and the reliability of a data warehouse, enabling organizations to leverage the full potential of their data assets. In this blog, we will explore the key components of a data lakehouse and how they work together to create a robust foundation for modern analytics.
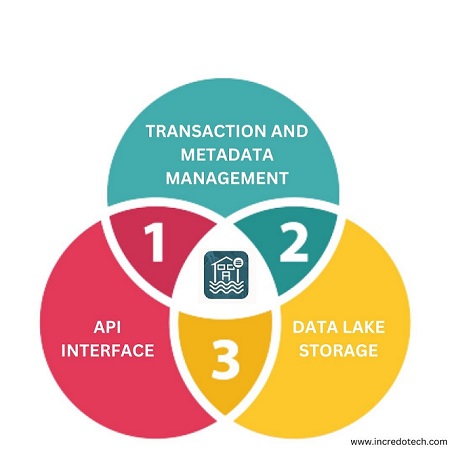
API Interfaces
Data lakehouse’s goal is to simplify the enterprise data estate, and one important feature that contributes to this goal is the platform’s capacity to enable users communicate with it in the language of their choice. In order for clients to access stored data, a lakehouse needs to provide a variety of APIs. These include the most well-known APIs for SQL and Spark as well as those on the consuming side for batch and stream ingestion. Despite its apparent simplicity, this layer is probably the most complicated in a data lakehouse because it must translate API functions to corresponding storage activities in the best way possible.
Transaction & Metadata Management
This is the layer which differentiates a lakehouse from a data lake. This layer ensure data in the lakehouse is accurate, complete and trusted and is thus critical for a good lakehouse platform. Following are the functions performed by this layer:
Transaction management:This layer’s primary purpose, which is made clear by its name, is to give the storage layer transactional capabilities. In general, data lake storage is a “append only” repository without transaction management tools. While a data lake may get away with this, a lakehouse needs the ACID capabilities that a DWH can offer to make sure it fulfils the dual purposes it offers. There are a variety of methods for delivering this functionality over a data lake storage, but one of the most well-liked is the delta lake format, which operates over the parquet file format and includes transaction capabilities.
Metadata management:Data lake storage is essentially just a file system that gives folders as a way to organise the data that is kept in the lakehouse. Through the addition of components like tables and views on top of this folder structure, metadata management makes consuming this data easier. Due to the enormous amount of data kept there, this feature not only facilitates consumption but also facilitates easy data discovery.
Data governance: Data governance has grown in importance when dealing with any company data due to the always expanding compliance requirements. A data governance layer that can audit and regulate access to all of the data kept inside the lakehouse is a requirement for a successful data lakehouse solution. This includes the ability to establish and implement access policies, label data, and keep access logs for tracability.
To guarantee that data in a lakehouse remains correct and dependable, extra tasks like data quality management or lineage tracking are typically combined with this layer.
Data Lake Storage
Given that a data lakehouse’s goal is to serve as the central enterprise knowledge hub, it’s critical that the storage layer satisfy the following essential characteristics:
Cost effective:Data lakehouse is typically a “append only” storage and is required to store enormous amounts of data. Once information has been digested into Data Lakehouse, it won’t be destroyed or archived for a very long time. Therefore, the storage must be less expensive than conventional DWH or database storage options. Utilising distributed computing tools like HDFS, which can store vast volumes of data on affordable hardware, this is accomplished.
Scalable:Data lakehouse storage must be scalable as data volume rises due to the always expanding amount of company data that will not be destroyed. In this case, distributed computing is beneficial since it offers horizonal scaling over commodity hardware.
Flexible:Data must be stored in various formats and at various ingestion rates in order for the data lakehouse to serve as the central knowledge repository. This is accomplished by storing structured, unstructured, and semi-structured types of data at parity utilizing blob and object storage formats.
Conclusion
A Data Lakehouse offers a scalable, adaptable, and trustworthy platform for storing, managing, and analysing data by fusing the greatest features of data lakes and data warehouses. Organisations can create a solid basis for modern analytics and unlock the full potential of their data assets by understanding the essential elements of a data lakehouse. Each component is crucial to the success of a data lakehouse deployment, from data intake and storage to processing frameworks, data catalogues, and analysis tools, allowing organisations to gain insightful information and make data-driven decisions in today’s data-driven environment.